
在图像生成领域,扩散模型已经带来了突破性的性能,那么生成蛋白质结构呢?研究人员开发了一种新的蛋白质合成扩散模型,称为 RoseTTAFold Diffusion(RFDiffusion),这种蛋白质是从零开始创造的,而非来自于自然界中早已存在的蛋白质。
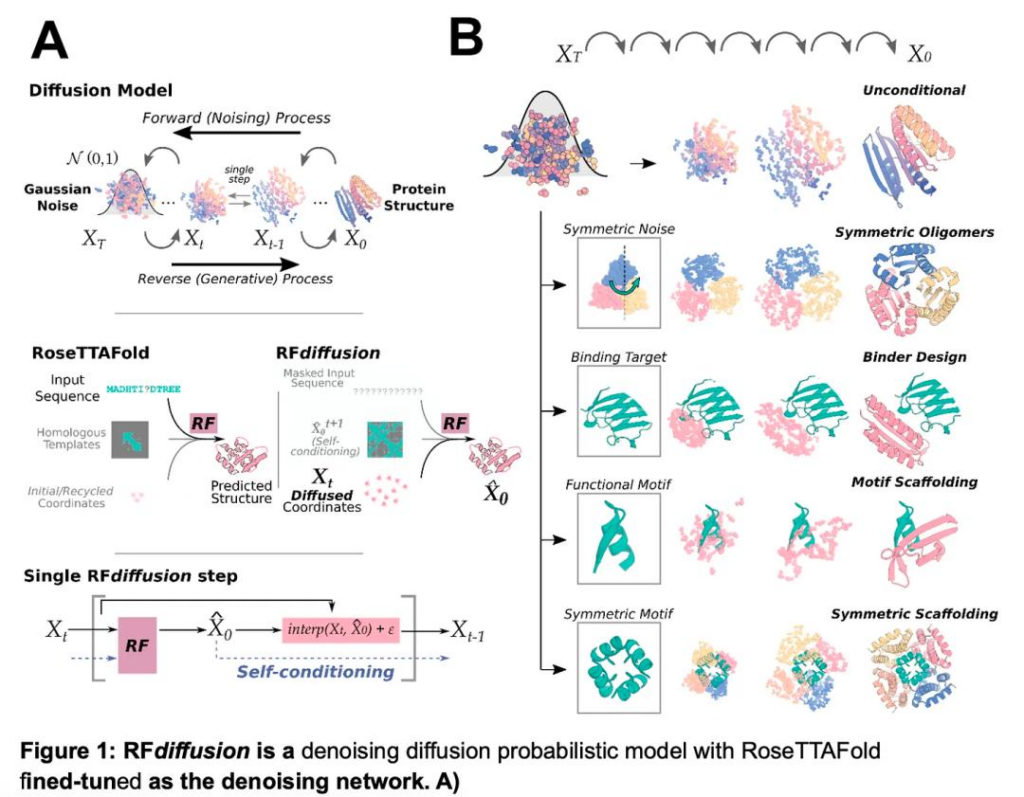
区分 de novo 蛋白质(在实验室中使用没有进化历史的氨基酸序列合成)与诸如 AlphaFold、 AlphaFold2 等系统(使用现有氨基酸序列数据预测蛋白质 3D 结构)十分重要。但值得注意的是,AlphaFold2 曾被用于验证 RDiffusion 研究的结果。
然后再谈谈最近的行业趋势。今天,在产业中实际使用的技术是什么?根据麦肯锡最近的 AI 全景报告 —— 并不是大型语言模型(Transformer)。特别说明,由于样本规模和代表性的限制,该报告中的调查结果可能无法准确反映所有公司的经验。
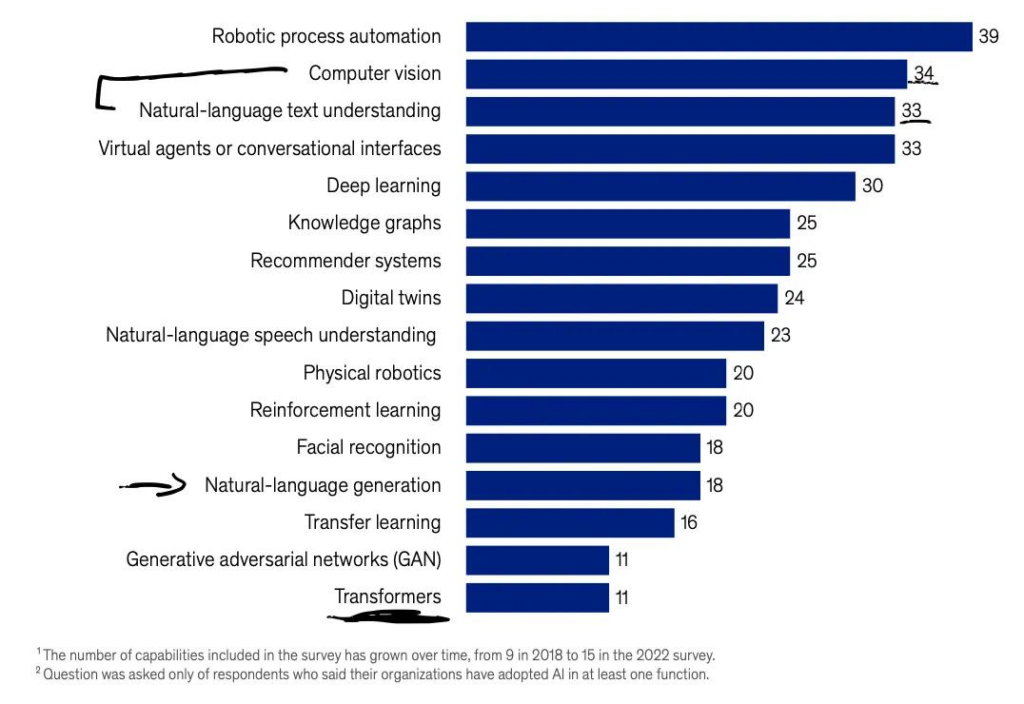
图源:麦肯锡 2022 年全景报告。
自然语言处理在行业内一直受到追捧,但其受欢迎程度经常被计算机视觉应用超越。但现在,我们第一次看到计算机视觉和自然语言处理几乎总是紧密联系在一起。
与此同时,自然语言文本理解(可能指文本分类)的受欢迎程度几乎是自然语言「生成」的两倍。请注意,自然语言生成的新闻通常会占据热点首页:如 GPT-3、Galactica、ChatGPT 等。(文本理解可能包括摘要,摘要也是「生成」的,所以我假设它在这里主要指的是类似分类的任务。那么反过来说,类别(categories)也是可以重叠的。)
值得注意的是,Transformer 的排名垫底。
似乎许多公司尚未采用类似 BERT 的语言模型编码器来进行文本理解和分类。相反,他们可能仍在使用基于词袋模型( bag-of-word-based)的分类器或递归神经网络。同样,类似 GPT 的模型解码器似乎还没有广泛应用于语言生成,因而文本生成可能仍严重依赖循环神经网络和其他传统方法。
基于下图,我发现了一些有趣的其他见解:
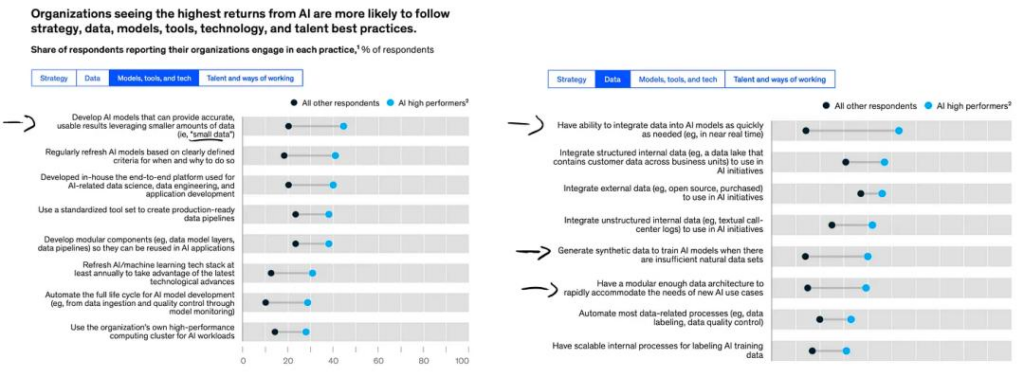
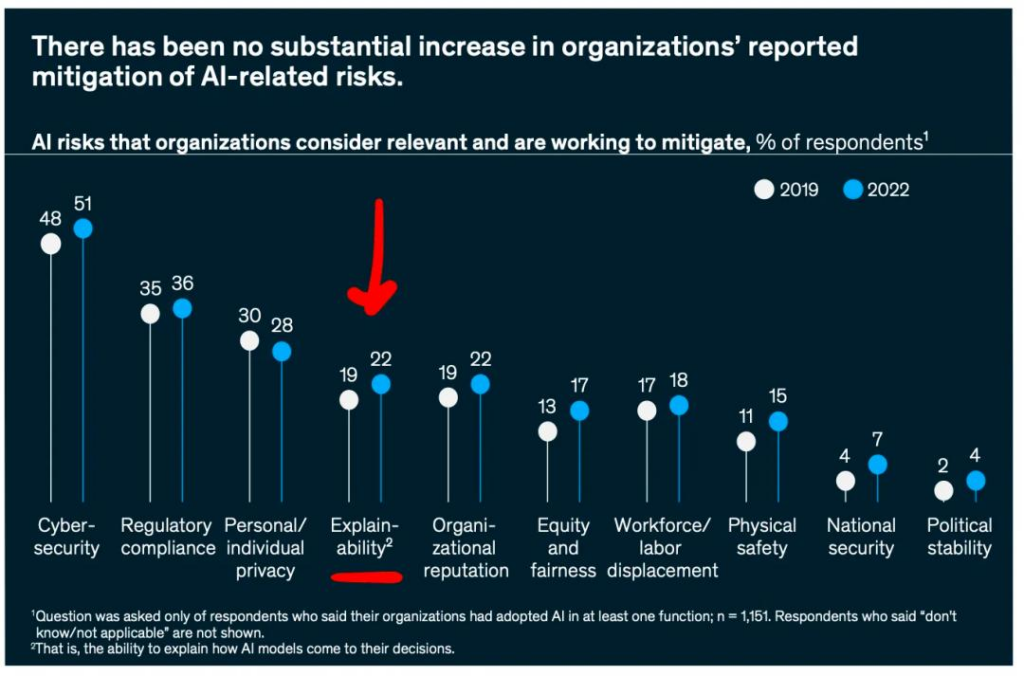
图源:2022 年麦肯锡 AI 全景报告。
能够利用「小数据」非常重要。当数据不可用时,生成合成数据的能力非常有用。
尽快将数据集成到 AI 模型中的能力是在竞争中脱颖而出的关键。那么,良好的软件框架和基础设备设置可能起到举足轻重的作用。
不幸的是,大多数高绩效公司迄今仍不关心模型的可解释性。

评论0